-
[Data Science] 분류 분석의 기본 개념Data Science/Data Science in R 2018. 12. 15. 11:09
목표 : 분류분석 기본 개념에 대해 이해해보자.
기본 개념
ㆍ지도학습(supervised learning) : 주어진 설명변수로부터 반응변수를 예측해내는 작업
ㆍ분류분석(classification) : 주어진 입력변수에 근거하여 범주형 반응변수를 예측하는 작업
ㆍ회귀분석(regression prediction) : 연속형과 수치형 반응변수를 예측하는 작업
분류분석의 예로써는 다음과 같으며, 일반적으로 '성공'은 1, '실패'는 0으로 나타낸다.
ㆍ신용카드 사용자의 다양한 변수를 사용하여 사용자가 디폴트(default, 채무불이행)할 확률을 계산한다.
ㆍ투자할 회사의 다양한 속성변수를 사용하여 투자가 성공할 확률을 계산한다.
ㆍ웹방문자정보,사이트정보,방문시간 등을 사용하여 특정 광고를 클릭할 확률을 계산한다.
분류분석에 대해서는, 성공-실패 두 가지 값을 가지는 반응변수만 고려할 것이며, 이를 이항분류분석 이라 한다.
* 이항분류분석의 목적
1) 미래 데이터에 대한 정확한 예측 : 기존의 데이터를 이용하여 아직 관측되지 않은 미래의 관측지를 가장 정확히 예측해내는 함수를 만들어내는 것
2) 변수 간의 관계의 이해 : 설명변수와 반응변수 간의 관계에 대한 이해를 돕는 것
1. 정확도 지표, 이항편차, 혼동행렬, ROC 곡선, AUC
1) 이항편차(binomial deviance) : 이항편차 값의 수식은 다음과 같으며, D값은 작을수록 좋은 모형이다.
앞으로 분석에 활용될 이항편차를 구하는 R함수는 다음과 정의하였다.
binomial_deviance <- function(y_obs, yhat){
epsilon = 0.0001
yhat = ifelse(yhat < epsilon, epsilon, yhat)
yhat = ifelse(yhat > 1-epsilon, 1-epsilon, yhat)
a = ifelse(y_obs==0, 0, y_obs * log(y_obs/yhat))
b = ifelse(y_obs==1, 0, (1-y_obs) * log((1-y_obs)/(1-yhat)))
return(2*sum(a + b))
}
2) 혼동행렬 : 머신러닝 혹은 통계학습에서 관측값 y와 예측값 yhat의 관계는 다음 혼동행렬 혹은 오차행렬로 요약할 수 있다.
행은 실제 클레스값, 열은 예측된 클레스 값, 행렬값은 각 경우에 해당하는 관측치 개수를 나타낸다.
위의 혼동행렬로부터 다양한 메트릭을 계산할 수 있다.(다음 공식들은 암기하고 있는게 좋다)
ㆍ정밀도 = TP / Phat
ㆍ재현율 = sensitivity = True Positive Rate = TPR = TP / P
ㆍFalse Positive Rate = FPR = FP / N
ㆍspecificity = True Neagative Rate(TNR) = TN / N
ㆍ정확도 = ACC = (TP + TN) / (P+ N)
ㆍF1 score 2TP / (2TP + FP + FN) : 정밀도와 재현율의 조화 평균
3) ROC(수신기 작동 특성) 곡선 : 분계점을 변화하면서 TPR과 FPR을 그린 곡선
ROC 곡선은 분계점에 따라 다른 분류분석 결과와 척도값을 낳는다. 다음은 분계점에 따른 TPR과 FPR의 값 변화이다.
1) 분계점이 1이면 모든 관측지를 False로 예측하고, TPR = FPR = 0이 된다.
2) 분계점이 0이면 모든 관측지를 True로 예측하고, TPR = FPR = 1이 된다.
분계점을 0에서 1로 변화시키면 FPR을 x축에, TPR을 y축에 나타낸 것이 ROC 곡선이다. ROC 곡선은 R에서 ROCR 라이브러리를 사용하면 간편하게 그릴수 있다.
즉, ROC곡선은 주어진 FPR(가로축)값에 대해 TPR(세로축)이 높을수록 더 정확한 것이므로, ROC 곡선이 위에 있는 모형이 더 예측 능력이 좋다.
4) ACU(Area Under ROC Curve : ROC 곡선 아래의 영역) : 모형의 정확도를 하나의 숫자로 요약하기 위한 지표
ROC 곡선 아래에 있는 영역의 면적이다. 0에서 1사이의 값을 가지며, 1에 가까울수록 평균 예측력이 높다.
2. 모형의 복잡도, 편향-분산 트레이드 오프, 모형 평가, 모형 선택, 교차 검증
* 여기서 먼저 알아야 할 개념 한가지는 과적합(Overfitting) 문제 이다.
ㆍ과적합 : 모형이 너무 모형에 사용된 데이터에 맞춰져서 아직 관측되지 않은 새로운 데이터에 적합하지 않는 상태.(즉, Tranining set data에 대해서만 너무 과하게 학습을 시키게 되면 발생되는 문제로써, 이러한 문제가 발생되면 Test set에서는 적합한 출력값을 이루어 내지 못하게 되는 상황이다.)
ㆍ과적합 문제 해결방법 : Training Set data를 학습 시, 추가적인 검증 데이터를 통해 검증해내면 방지가 가능하다.
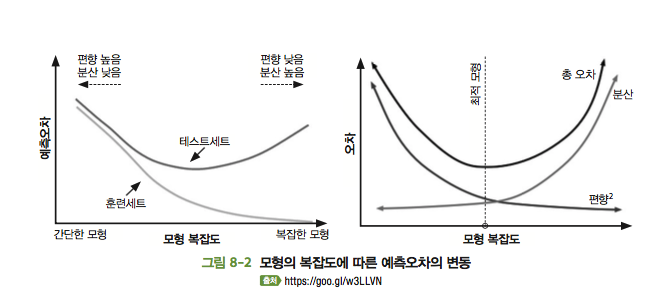
1) 모형의 복잡도, 훈련셋 오차율, 테스트셋 오차율, 편향, 분산 사이의 관계에 대해서는 다음 그림을 참고하자.
첫 번째 그림을 보면, 다음과 같은 사항들을 통해 적당히 복잡한 모형이 좋음을 알 수 있다.(난 "적당해야 한다"는 말이 제일 싫다!!!)
① Test set은 모형이 복잡할 수록 정확도가 떨어진다.
② Training set은 모형이 복잡할수록 정확하다.
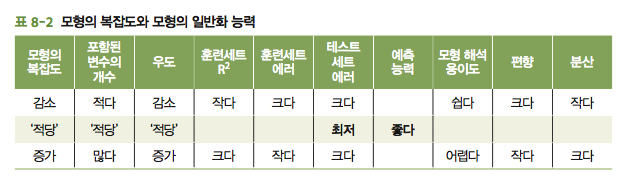
2) 모형의 복잡도와 관련된 다양한 변인들의 관계는 다음 표처럼 요약 가능하다.
결론은, 모형 평가(model assessment)와 모형 선택(model selection)은 데이터를 효율적으로 사용해 과적합을 방지하고, 일반화 능력(generalization ability)이 좋은 모형을 선택하는 것을 돕는다.
3) 정확한 모형 평가를 위해서는 데이터를 개념적으로 세 가지 형태로 구분해야한다.
ㆍ훈련 데이터 세트 : 모형의 적합과 모수의 추정에 사용된다.
ㆍ검증 데이터 세트 : 파라미터 튜닝과 변수 선택과 모형 선택에 사용
ㆍ테스트 데이터 세트 : 모형 적합과 모형 선택이 끝난 후 최종 모형의 오류확률(error rate)를 측정 / 추정하기 위해 사용
Q. 그럼 전체 데이터에서 이 Data Set의 비중 어떻게 두는 것이 가장 현명할까?
A. 개인적인 의견이지만 50:25:25 혹은 60:20:20이 가장 좋아보인다.4) 모형 선택과 평가를 위한 방법은 다음과 같다.① 데이터를 랜덤하게 나누고(예를 들면, 50:25:25)② 훈련 데이터를 이용해 모형을 적합하고③ 검증 데이터세트를 이용해 적합한 모형 중 최종 모형을 선택한 후
④ 테스트 데이터 세트를 사용해 최종 모형의 성능을 측정하는 것이다.
3. 분류 분석 문제 접근법
최종적으로 이러한 개념을 모두 익혔으면 다음처럼 분류 분석 문제를 접근할 수 있다. 이 방식은 여러가지 예제를 접하며, 익숙해지는 것이 좋으므로 꼭 다음 게시글의 예제들을 통해 실습해 보도록 하자
크게 볼 때는 다음과 같다.
1) 훈련세트로 (전체 데이터의 60%) 다양한 모형을 적합한다.
2) 검증세트로 (전체 데이터의 20%) 모형을 평가, 비교하고, 최종 모형을 선택한다.
3) 테스트세트로 (전체 데이터의 20%) 선발된 최종 모형의 일반화 능력을 계산한다.
이를 세부적인 단계로 보면 다음과 같다. 이 단계들은 매우 중요하다.
1) 데이터의 구조를 파악한다. y 변수의 인코딩, x 변수의 변수형 등을 연구한다.
2) 데이터를 훈련세트, 검증세트, 테스트세트로 나눈다.
3) 시각화와 간단한 통계로 y 변수와 x 변수간의 관계를 파악한다.
ㆍ어떤 x 변수가 반응변수와 상관 관계가 높은가
ㆍ이상치는 없는가?
ㆍ변환이 필요한 x변수는 없는가?
4) 시각화와 간단한 통계로 x변수들 간의 관계를 파악한다.
ㆍ상관 관계가 아주 높은 것은 없는가?
ㆍ비선형적인 관계는 없는가?
ㆍ이상치는 없는가?
5) 다양한 분류분석 모형을 적합해본다.
ㆍ로지스틱 분석
ㆍ라쏘
ㆍ트리 모형
ㆍ랜덤 포레스트
ㆍ부스팅
6) 각 분류 분석 모형에서 다음 내용을 살표보자
ㆍ변수의 유의성 : 모형이 말이 되는지, 기대한 변수가 중요한 변수로 선정되었는지
ㆍ적절한 시각화 : 로지스틱 분석, 트리 모형 등 모형마다 도움이 되는 시각화를 제공
ㆍ모형의 정확도 : 교차검증을 이용하여 검증세트에서 계산하여야 한다.
7) 검증세트를 사용하여 최종모형을 선택한다. 즉, 예측 성능이 가장 좋은 모형을 최종 모형으로 선발한다.
8) 테스트 세트를 사용하여 최종 선발된 모형의 일반화 능력을 살펴본다.
다음은, "Adult" 데이터와 이때까지의 내용을 통해 GLM(로지스틱 분석)을 응용해보자.
* 참고문헌 : 실리콘밸리 데이터 과학자가 알려주는 따라하며 배우는 데이터 과학(저자 : 권재명)
'Data Science > Data Science in R' 카테고리의 다른 글
[Data Science] Wiscinsin Breast Cancer(위스콘신 유방암) 데이터① 분류 분석 (0) 2018.12.16 [Data Science] Adult 데이터로 알아보는 분류분석 모형 개념 (1) 2018.12.15 [Data Science] 데이터 종류에 따른 분석 기법 (0) 2018.10.25 [Data Science 기초] IMDB 영화 정보 데이터 시각화 및 분석 (0) 2018.10.24 [Data Science 기초] 데이터 시각화 응용 - 변수의 종류에 따른 시각화 (0) 2018.10.23