-
CNN(Convolution Neural Network) 구조Deep-Learning/[Vision] 이론 2020. 1. 29. 16:32
1. CNN 개요
영상 인식 알고리즘에서 높은 정확도(좋은 결과)를 얻기위해서는 사전에 많은 처리 과정이 필요하다.
그렇기에 기존 MLP를 바로 적용하기엔 어려움이 많다. 먼저, MLP의 문제점을 살펴보자.
1) MLP의 문제점
이상적인 ML이라면 Training Data만 적절히 넣어주면 분류가 잘되는 모습을 기대할 것이지만 현실은 그렇지 못하다. 따라서, 기존 MLP를 이용해 nets 구조를 특수한 형태로 변형시켜 사용해야 한다.
그렇다면, 2D 이미지가 갖는 특성을 어떻게 활용할까?
아래의 그림처럼 MLP를 이용해 16*16크기의 손글씨 이미지를 인식하는 경우를 살펴보자
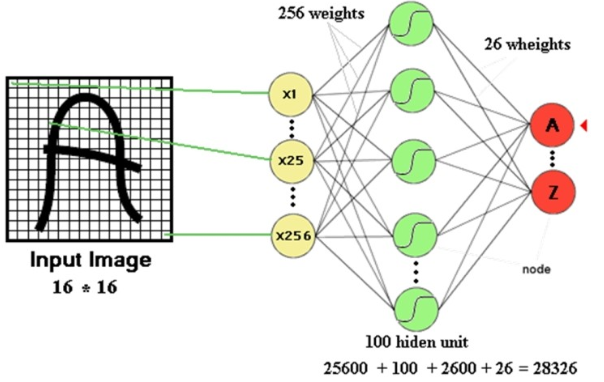
필기체 인식을 위해 위 그림처럼
256개의 input unit
100개의 hidden unit
26개의 output unit
으로 구성이 되면 해당 net에 필요한 weight와 bias는 총 28326개이다.
폰트가 커지거나 hidden layer가 2단 이상이면 파라미터의 개수는 엄청 커지게 된다는 것이다.
기존 신경망의 문제점을 살펴보기 위해 다음 예를 보자.

위 그림처럼 전체 글자에서 단지 2픽셀값만 달라지거나 이동해도 새로운 training data로 처리해줘야하는 문제점이 있다. 또한, 글자가 달라지거나, 회전되거나, 변형이 생긴다면 좋은 결과를 기대하기 어렵다.
즉, 기존 MLP는 글자의 topology는 고려하지 않고 raw data에 대해서만 처리하기에 엄청난 training data를 필요로 하고 그에 따른 시간도 소요해야 하는 문제점이 있다.
정리하면, 기존 MLP의 문제점은 아래와 같다.
(1) 학습 시간
(2) 망의 크기
(3) 변수의 개수
'Deep-Learning > [Vision] 이론' 카테고리의 다른 글
[Semantic Segmentation] Mean Intersection over Union(MIoU) (0) 2020.03.09 [Semantic Segmentation] Semantic Segmentation 목적 (0) 2020.01.29