-
[Semantic Segmentation] SegNet 원리Deep-Learning/[Vision] 논문 리뷰 2020. 2. 3. 13:47
* 논문 : https://arxiv.org/pdf/1511.00561.pdf
1. Semantic Segmentation의 목적 : https://kuklife.tistory.com/118?category=872136
2. Semantic Segmentation 알고리즘 - SegNet
SegNet 논문은 2016년 10월 경, Vijay Badrinarayanan, Alex Kendall, Roberto Cipolla에 의해 작성되었다.
SegNet의 주된 목적은 road, building, cars, pedestrians 등 자율주행과 관련된 구조들을 pixel-wise semantic segmentation 하기 위해 설계된 모델이다.(자율주행 연구 분야에서 큰 역할을 한 모델이라고 한다.)
뒤에 자세히 설명하겠지만, encode와 decoder로 나뉘는데 encoder network는 VGG16의 13개 convolution layers를 동일하게 사용하기에 VGG16에 대해서 간단히 설명 후 논문 리뷰를 진행해보겠다.
※ VGG16의 구조
VGGNet은 옥스퍼드 대학의 연구팀 VGG에 의해 개발된 모델로써, 2014년 이미지넷 이미지 인식 대회에서 준우승한 모델이다. 여기서 말하는 VGGNet16은 16개의 층으로 이루어진 모델을 의미한다.
VGG 연구팀은 AlexNet, VGG-F, VGG-M, VGG-S에서 사용되던 Local Respnse Normalization(LRN)이 A구조와 A-LAN 구조의 성능을 비교함으로써 성능 향상에 별로 효과가 없다고 실험을 통해 확인했다. 그래서 더 깊은 B, C, D, E 구조(11층, 13층, 16층, 19층)로 깊어지면서 분류 에러가 감소하는 것을 관찰했다. 즉, 깊어질수록 성능이 좋아진다는 것이었다.
VGGNet의 구조를 보기 전 집고 넘어가야 할 사항이 있다. 그것은 바로 3x3 필터로 두 차례 Convolution 하는 것과 5x5 필터로 한 번 Convolution 하는 것이 결과적으로 동일한 사이즈의 특성맵을 산출한다는 것이다. 또한, 3x3 필터로 세차례 Convolution 하는 것은 7x7 필터로 한 번 Convolution 하는 것과 대응된다.

3x3 필터로 세차례 Convolution 하는 것이 7x7 필터로 한 번 Convolution 하는 것보다 나은 점이 무엇일까?
먼저, 가중치 또는 파라미터 갯수 차이이다. 3x3 필터가 3개면 총 27개의 가중치를 갖는다. 반면 7x7 필터는 49개의 가중치를 갖는다. CNN에서 가중치는 모두 훈련에 필요한 것들이므로 가중치가 적다는 것은 그만큼 훈련시켜야 할 것의 갯수가 작아진다. 즉, 학습의 속도가 빨라지며, 그와 동시에 층의 개수가 늘어나면서 특성에 비선형성을 더 증가시키기 때문에 특성이 점점 더 유용해진다.
그럼 이제 VGG16의 구조를 살펴보자.

VGG16 구조 1) Input : 224 x 224 x 3의 이미지(224 x 224 x RGB 채널)를 입력받는다.
2) 1층(Conv1_1) : 64개의 3x3x3 필터로 입력 이미지를 Convolution 해준다. zero padding은 1만큼 해줬고, Convolution Stride는 1로 설정해준다. zero padding과 convolution stride에 대한 설정은 모든 Convolution layer에서 모두 동일하니 다음 층부터는 설명을 생략하겠다. 결과적으로 64장의 224x224 feature map(224x224x64)들이 생성된다.
활성화를 시키기 위해 ReLU 함수가 적용되었으며 ReLU함수는 마지막 16층을 제외하고는 항상 적용되니 이 또한 다음 층부터는 설명을 생략하겠다.
3) 2층(Conv1_2) : 64개의 3x3x64 필터로 feature map을 Convolution해준다. 결과적으로 64장의 224x224 feature map(224x224x64)들이 생성된다. 그 다음에 2x2 max pooling을 stride 2로 적용함으로써 feature map의 사이즈를 112x112x64로 줄인다.
* Convⓝ_ⓝ으로 표현한 이유는 해상도를 줄여주는 max pooling 전까지의 층등을 한 모듈로 볼 수 있기 때문이다.
3) 3층(Con2_1) : 128개의 3x3x64 필터로 feature map을 Convolution 해준다. 결과적으로 128장의 112x112 feature map들이 산출된다.
...생략...
14) 14층(FC1) : 4096개의 7x7x512 필터로 feature map을 Convolution 한다. feature맵의 크기와 동일한 사이즈의 필터이므로 결과적으로 1x1 사이즈의 4096장의 feature map이 산출된다. 이것을 하나로 연결해주면 4096차원의 vector가 된다. 즉, 4096개의 뉴런을 볼 수 있다. 훈련 시에는 dropout을 적용한다.
15) 15층(FC2) : 4096개의 뉴런으로 구성해준다. fc1층의 4096개의 뉴런과 연결된다. 훈련 시에는 dropout을 적용한다.
16) 16층(FC3) : 1000개의 뉴런으로 구성된다. fc2층의 1000개의 뉴런과 연결된다. 출력값들은 softmax 함수로 활성화된다. 1000개의 뉴런으로 구성되었다는 것은 1000개의 class로 분류하는 목적으로 만들어진 Network란 뜻이다.
(1) Architecture
위에서 잠시 언급했듯이, SegNet은 그림과 같이 Encoder와 Decoder로 나뉘게 된다.
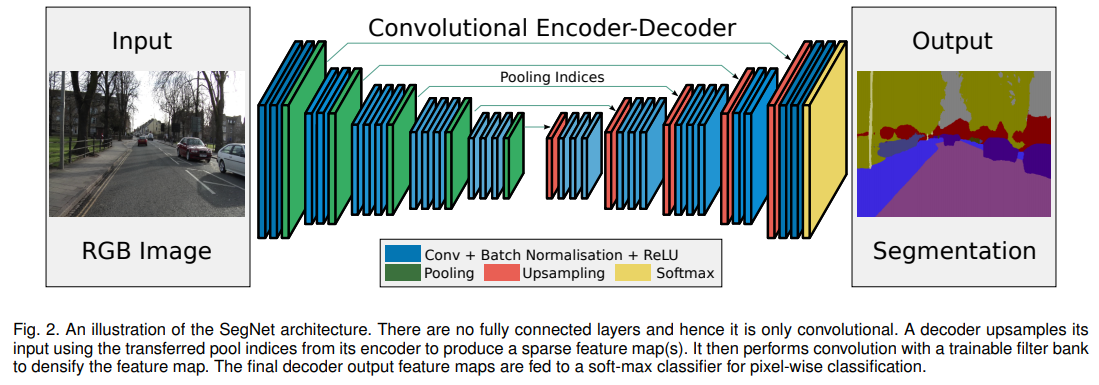
SegNet Architecture 1) Encoder Network
- Convolution과 Max pooling을 수행하는데, 이 Net은 VGG16에서 FCL을 뺀 13개의 Convolution Layer를 그대로 사용하였다.
- 2x2 Max pooling을 수행하는 동안에 해당하는 Max Pooling Indeices(위치정보를 의미)를 저장한다.
2) Decoder Network

Max pooling Indices를 사용한 Upsampling - Upsampling과 Convolution을 수행하며, 마지막 Layer에는 각 픽셀의 class 예측을 위한 softmax classifier가 존재한다.
- Upsampling은 위의 그림과 같이 Encoder에서 저장한 Max Pooling Indeices를 수신받아 수행한다.
- 마지막 Layer에서는 K-class softmax 분류기를 사용하여 각 픽셀의 클래스를 예측한다.
이러한 Encoder Net의 Max Pooling Index들을 재사용(즉, SegNet의 Decoder 구조처럼)하면 장점이 몇 가지 있다.
1) boundary delineation(번역 : 경계 묘사)를 향상시킬 수 있다.
2) end-to-end를 가능케하는 파라미터 개수를 줄일 수 있다.
3) 이러한 upsampling 방식은 모든 encoder-decoder 형식에 통합될 수 있다.
여기서, 관심을 가져야 할 부분은 SegNet이 U-Net & DoconvNet과 무엇이 다른가이다.
* U-Net 설명 : https://kuklife.tistory.com/119?category=872135
1) DeconvNet과의 차이점
- Unpooling이라는 유사한 Upsampling 방식이 사용되지만
- SegNet은 FCL이 존재하지 않는다.
2) U-Net과의 차이점
- U-Net은 주로 bio 이미지에서 사용되며
- Pooling Indices를 사용하는 대신 전체 feature map이 encoder에서 decoder로 전송된 다음 연결하여 Convolution을 수행한다.
- 이는 모델을 더 크게 만들며 더 많은 메모리 사용을 하게 된다.
(2) Result
다음은 SegNet의 Result이다. 두 개의 Data-set을 사용하였으며, 하나는 Road Scene Segmentation을 위한 Camvid data-set, 나머지 하나는 Indoor Scene Segmentation을 위한 SUM RGB-D data-set이다.
1) Camvid data-set for Road Scene Segmentation

- 기존 접근법과 비교하였을 때, 위 표에서 알 수 있듯 SegNet이 많은 Classes에 대해 가장 좋은 결과를 가져왔음을 볼 수 있다.

- Deep Learning 접근법과 비교하였을 때, SegNet은 G(global average accuracy)와 C(class average accuracy), mIoU와 BF(Boundary F1-measure) 모두 가장 높았다.

- 위 그림은 outperform이며, SegNet의 결과가 segmentation이 가장 잘됨을 보여준다.
2) SUN RGB-D Dataset for Indoor Scene Segmentation
이 결과는 qualuatative results를 확인할 수 있는 SUN RGB-D data-set이다.

- 다른 Deep Learning 접근법과 비교해보았을 때, mIOU에서 DeepLabv1이 가장 우수하였지만 나머지는 SegNet이 가장 우수함을 보였다.


- Outperform을 보면 큰 사이즈의 classes는 높은 정확도를 보이지만, 작은 사이즈의 classes는 낮은 정확도를 보인다.
3) Memory and Inference Time

- SegNet은 FCN과 DeepLabv1과 비교하였을 때, decoder 구조를 가지고 있기에 더 느린 것을 볼 수 있다. 또한, FCL을 사용하지 않기에 DeconvNet보다는 빠름을 보였다.
- 또한, SegNet은 Training과 Testing 간에 많은 메모리가 요구되지 않으며, Model size는 FCN과 DeconvNet보다 훨씬 적다.
'Deep-Learning > [Vision] 논문 리뷰' 카테고리의 다른 글
[GAN] Pixel-Level Domain Transfer(DTGAN) 논문 리뷰 (0) 2020.08.06 [Inpainting] Context Encoder(CE) 원리 (0) 2020.05.26 [Semantic Segmentation] DeepLab v3+ 원리 (1) 2020.02.05 [Semantic Segmentation] U-Net 원리 (1) 2020.01.31 [Semantic Segmentation] FCN 원리 (0) 2020.01.29