-
[Object detection] YOLO v4 논문 리뷰Deep-Learning/[Vision] 논문 리뷰 2021. 6. 28. 11:07
- YOLOv4: Optimal Speed and Accuracy of Object Detection
- YOLO 시리즈, 2020년 초에 공개
- Real-time object detection 에서 유명한 시리즈 모델
- 논문: https://arxiv.org/pdf/2004.10934.pdf
요약
몇몇의 feature들은 특정한 모델이나 문제에 국한되어 동작하거나, 소규모 데이터셋에 대해서만 동작한다. 하지만, Object detection을 수행하기 위해서는 universal한 features에 대하여 동작가능해야 한다. 대표적으로 Weighted-Residual-Connections(WRC), Crss-Stage-Partial-Connections(CSP), Cross mini-Batch Normalization(CmBN), Self-adversarial-training(SAT), Mish-activation이 있다.
이에 본 연구는 아래와 같은 features들을 적용하고, 이들 중 몇 개를 조합하여 SOTA를 달성하고자 한다.
- WRC, CSP, CmBN, SAT, Mish activation, Mosaic data augmentation, DropBlock regularization, CIoU loss
- 정확도: MS COCO 기준 AP: 43.5% (AP_50: 65.7%)
- 속도: 테슬라 V100 기준 ~65FPS
INTRODUCTION
본 논문의 목적은 Object detector의 높은 정확도와 빠른 처리 속도를 만족시키는 것이다. YOLO v4는 기존 GPU를 사용하여 그림 1과 같이 두 개의 목적을 모두 달성하였다
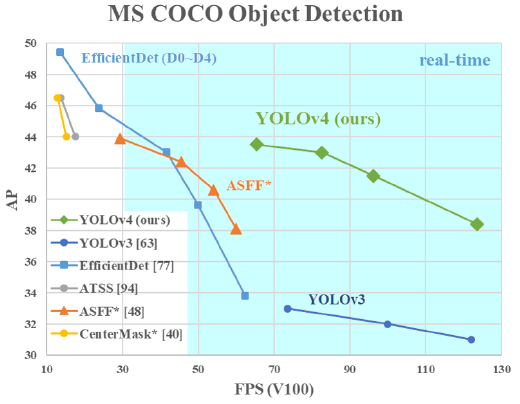
그림 1. YOLO v4와 다른 SOTA 모델의 비교 본 논문의 기여는 다음과 같다.
1. 효율적이며 강력한 object detection model을 개발하였다. 이는 1080Ti 또는 2080Ti GPU를 사용하는 사람이라면 빠른 속도로 학습이 가능하고, 정확한 결과를 얻을 수 있다.
2. detector를 학습하는 동안, 사용될 수 있는 최신의 Bag-of-Freebias 및 Bag-of-Specials 기법들이 주는 영향에 대해 검증하였다.
3. 단일 GPU training에 보다 효율적이며 적합하도록, CBN, PAN, SAM 등을 포함한 최신 기법들을 수정하여 적용하였다.
Related Works
2.1. Object detection models

그림 2. Object detector의 구성 최신의 detector들은 일반적으로 2개의 부분(backbone과 head)으로 구성되어 있다.
1) Backbone: ImageNet을 이용하여 Per-trained 됨
- GPU 연산을 사용하는 backbone들: VGG, ResNet, ResNext, DenseNet 등
- CPU 연산을 사용하는 backbone들: SqueezeNet, MobileNet, ShuffleNet 등
2) Head: Object에 대한 Class와 Bboxd를 예측
- One-stage & anchor-based models: YOLO 시리즈, SSD, RetinaNet 등
- One-stage & anchor-free models: CenterNet, CornerNet, FCOS 등
- Two-stage & anchor-based mdoels: R-CNN 계열 모델(Fast R-CNN, Faster R-CNN, Mask R-CNN, Bibra R-CNN 등)
- Two-stage & anchor-free models: RedPoints 등
* 여기서, anchor-free model은 anchor 없이 object를 바로 찾을 수 있는 기법을 의미한다. anchor 없이 object를 찾는 방법은 크게 두 가지 방법으로 나뉜다.
1) 키포인트를 이용하여 object의 위치를 예측하는 keypoint-based 방법
2) object의 중앙을 예측한 후, positive인 경우, object boundary의 거리를 예측하는 center-based 방법
3) Neck: 최근에 개발된 detector들은 backbone과 head 사이에 약간의 layers들을 삽입하였으며, 이러한 layers들은 보통 서로 다른 stages들로부터 온 feature maps들을 모으는데 사용한다. 보통 몇몇의 bottom-up paths 와 top-down paths로 구섳되며, 이러한 메커니즘을 구비한 네트워크는 아래와 같다.
- Feature Pyramid Network (FPN), Path Aggregation Network (PAN), BiFPN, NAS-FPN 등
4) Others: Object detection을 위해 새로운 backbone이나 새롭게 전체 model을 구축한 연구들
- 새로운 backbone: DetNet, DetNAS 등
- 새롭게 전체 model을 구축: SpineNet, HitDetector 등
'Deep-Learning > [Vision] 논문 리뷰' 카테고리의 다른 글
[GNN] HFGN 논문 리뷰 (0) 2021.04.23 [GNN] NGNN 논문 리뷰 (0) 2021.04.05 [GAN] Pixel-Level Domain Transfer(DTGAN) 논문 리뷰 (0) 2020.08.06 [Inpainting] Context Encoder(CE) 원리 (0) 2020.05.26 [Semantic Segmentation] DeepLab v3+ 원리 (1) 2020.02.05