-
금융권에서 경험한 NLP 일기장 - 1. DAPTDeep-Learning/[NLP] 이론 2023. 11. 10. 19:30
신한은행에서 AI Research Engineer로 재직하며 Document AI와 LLM 분야에서 다양한 연구와 과제를 수행했었다. 특히, 유능한 사람들이 만들어준 한국어 NLP 모델을 금융에 잘 써먹기 위해서는 Domain Adaptive pre-training (이하 DAPT)의 지식이 필수적이다. 이에 DAPT를 중심으로 직접 겪으며 미리 알았으면 좋았을 이론들과 나의 경험, 그리고 고찰들을 간단하게 정리해보았다.
* Vision을 전공했다보니 NLP 지식 습득을 위해 많은 고생을 했었던거 같다ㅠㅠ 그렇기에 필수적으로 알아야할 부분만 정리한 것이니 자세한 내용이 궁금하다면 원논문을 보는걸 권장! 다 쓰고 보니 너무 두서없이 적은거같네...
1. Tokenizer for Wordpiece vs. Sentencepiece vs. BPE(Byte-Pair Encoding)
2. KoBERT vs. KoRoBERTa vs. KoELECTRA
3. 내가 했던 DAPT (domain adaptive pre-training)
4. Re-ranking (Triplet loss (SentenceBERT)와 In-batch Random Negative Sampling(DPR))1. Wordpiece vs. Sentencepiece vs. BPE (Byte-Pair Encoding)
Wordpiece, Sentencepiec, BPE는 모두 텍스트 데이터를 처리하기 위한 토크나이징 방법이다. 각 방법이 어떻게 다른지 알아보자
1) Wordpiece

- Wordpiece에서 "#"의 의미: "#"은 단어의 일부분(subword)나 조각을 나타내는데 사용된다. 특히, 단어의 시작 부분이 아닌 중간 또는 끝 부분에 있는 subword를 표시할 때 사용한다.
- wordpiece의 작동원리:
step1. 초기 분할: 초기에는 모든 단어를 개별 문자로 분할
step2. 토큰 합치기: 가장 빈번하게 나타나는 문자 조합을 찾아 이를 하나의 토큰으로 만든다.
step3. subword 표시: 이미 생성된 단어의 일부가 아닌 새로운 조합을 나타낼 때, "#"기호를 사용하여 이를 구분한다.
- 예시: "unhappiness"라는 단어가 있다면, "un", "#happy", "#ness"와 같이 분할될 수 있습니다. 여기서 "un"은 독립적인 단어 조각이고, "#happy"와 "#ness"는 "happiness"의 일부분을 나타냅니다.
2) Sentencepiece
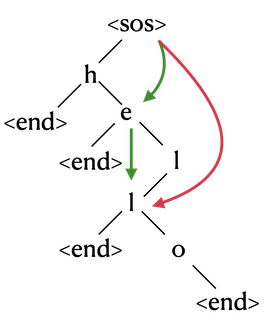
- Sentencepiece 에서 사용되는 "_" 기호의 의미와 작동 원리는 아래와 같다.
step1. 언어 중립적 분할: sentencepiece는 언어에 의존하지 않는 방식으로 텍스트를 처리한다. 이는 특히 다양한 언으를 한 번에 처리해야 할 때 유용하다.
step2. 모델학습: 데이터셋에 가장 효율적인 무자열 조각의 조합을 학습하며, 이 과정에서 데이터 내의 가장 일반적인 패턴을 인식하고 이를 기반으로 토큰을 생성한다.
step3. 토큰 생성: 학습된 모델을 바탕으로 입력된 텍스트를 토큰으로 분리한다. 이때 "_" 기호를 사용하여 새로운 단어의 시작 부분을 표시한다.
3) BPE: BPE는 "#"과 같은 특정 기호를 사용하지 않고, 문자열 쌍의 반복적인 합치기를 통해 아래와 같은 단계로 토크나이징한다.

step1. 초기화: 모든 단어를 기본 문자 단위로 분할하고, 단어의 끝을 표시하기 위해 종종 eos 기호를 사용한다.
step2. pair 합치기: 가장 빈도가 높은 인접 문자 쌍을 찾아 합치는 과정을 반복하면서 더 긴 문자열을 생성해나간다.
- BPE는 wordpiece와 비교할 때, 각각의 subword를 구분하는 특정 기호 대신 전체 단어나 문자열의 반복적인 합치기에 더 중점을 둡니다. BPE는 특히 데이터에 자주 나타나는 패턴이나 문자열을 효과적으로 인코딩하는 데 유용하다.
2. KoBERT vs. KoRoBERTa vs. KoELECTRA
위 3개는 기존 영문 언어모델을 한국어 특화 모델로 Pre-training한 모델이다. 한국어는 문법적, 문화적, 언어적 특성이 영어와 많이 다르기 때문에, 이러한 차이점들을 반영하기 위해 특화된 모델이 개발되었다. (이름에서 충분히 원모델명을 알 수 있으니 자세한 설명은 패스)
이들 모델은 각각 다음과 같은 차이점을 가지고 있다.
1) KoBERT: SKT에서 개발한 KoBERT는 위키, 뉴스 등에서 수집한 약 5천만 문장을 통해 학습되었고, 한국어의 불규칙한 언어 변화를 반영하기 위해 wordpiece가 아닌 sentencepiece를 사용한 것이 특징이다. (en-BERT는 wordpiece를 사용함)
2) KoELECTRA: ELECTRA는 BERT와 유하사지만, Discriminator와 Generator를 활용하여 가짜 단어를 감지하는 방식으로 학습됐다. 이에 적은 데이터로 학습하더라도 꽤나 좋은 성능을 보이는 모델로 유명하다. WordPiece 토큰화를 사용하여 34GB의 한국어 텍스트를 학습하였으며, 한국어 위키피디아, 나무위키, 신문, 모두 코퍼스 등에서 수집하였다고 한다.
3) KoRoBERTa: KoRoBERTa는 약 750MB의 한국어 텍스트로 SentencePiece 토크나이저를 사용하여 학습하였다.
누군가 "그래서 어떤 모델이 좋아?" 라고 묻는다면 나는 무조건 "실험을 돌려봐야지"라고 답한다. 다양한 실험이 있었지만, 흔히 사용되는 NLP task를 기준으로 어떤 모델이 우수했는가를 설명해보겠다. (이건 정말 내 개인적인 실험 고찰이기 때문에 정답은 아니다. 정답은 "데이터마다 결과는 다르다." 이다.)
1) NER task
- 한줄 요약: RoBERTa >>> BERT >= Electra
- 상황마다 다르지만, 데이터가 충분하다면 나의 선택은 무조건 "RoBERTa"이다. 특히, large 모델은 놀라울 정도의 NER 성능을 보여준다. 아무래도 선행학습된 데이터가 많고, BERT보다 많은 학습을 했기 때문인거 같다.
- KoELECTRA는 내가 해본 task에서 NER에서 성능이 그렇게 우수하지 못했다. Document AI에서 정보추출은 라벨링의 영향을 크게 받는다. 그래서 조금씩 늘려가며 결과를 봐야하기에 '데이터가 얼마 없으니 electra 써야겠다' 라고 생각했지만 100개의 라벨로도 BERT나 RoBERTa가 근소한 차이로 우수했다. (많아질수록 RoBERTa가 압도함)
2) Classification
- 분류할 대상의 양이 100개 미만이고, 분포가 클레스 별로 적당하다면 이 task 또한 KoRoBERTa가 우수하다.
- 하지만, 분류할 대상이 너무나도 많은데, 데이터도 적으며, 분포는 개판(?)이고, 발생할 수 있는 문장의 경우의 수가 많다면(distribution이 높다면) KoElectra를 사용하여 생성 task로 푸는걸 권장한다.
3) Ranking (Embedding Search)
- 사실 Ranking은 데이터 빨이 너무나도 크다. 하지만 baseline은 필요한 법..
- 데이터가 준비되어서 모델 단위의 비교실험으로 넘어왔다면 사실 Classification과 비슷한 결과일 것이다.
- 하지만, 데이터가 잘 준비되었다 라는 것은 RoBERTa가 압승할 것이란 예고편이 아닐까?
3. 내가 했던 DAPT (domain adaptive pre-training)
* 좋은 참고 자료: https://yangoos57.github.io/blog/DeepLearning/paper/Finetuning/Finetuning/

- "Don't Stop Pretraining: Adapt Language Models to Domains and Tasks"은 ACL 2020에서 BEST PAPER를 수상한 논문이자, NLP에 눈을 뜨게 해준 고마운 논문이다. 외부 스터디를 통해 알게된 이론인데 특정 도메인에 계신 분들과 특정 도메인 데이터를 부어본 사람 모두가 극찬했다. 만약, 독자가 특정 도메인에 종사한다면 DAPT를 꼭 한번쯤 써봤으면 좋겠다.
- DAPT를 써본 사람들은 노력대비 성능 향상이 거의 공짜(?) 라는 것을 알 것이다. 기존에 정제되지 않은 데이터가 많다면 약간의 전처리와 코드 몇 줄로 downtream task의 성능을 엄청나게 끌어올릴 수 있다. 내가 수행했던 과제 중 DAPT를 하니 성능이 14%까지 올라간 모델도 있었다. 약간의 전략은 있었지만, 그래도 이건 엄청난 성능 향상 아닌가..?

1) DAPT가 가능한 이유: Subword Embedding
- DAPT가 가능한 이유는 BERT가 subword 방식으로 이루어져있기 때문이다. subword embedding은 word embedding에서 발생하는 oov 문제를 해결하기 위해 제안된 방식이다.
- NLP 모델을 학습하기 위해 학습에 사용되는 데이터의 단어집을 Vocab 이라고 한다. vocab은 문장들을 단어로 분리하고, 이를 숫자로 encoding 하는 과정에 활용된다. 이러한 특성상 embedding 방식은 vocab에 없는 경우 해당 단어를 UNK(unknown의 약자)으로 토크나이징 한다. (<- 이러한 상황을 OOV라고 한다.)
- Subword Embedding은 Vocab에 없는 단어일지라도 하위 단어의 조합을 통해 단어를 생성할 수 있어 OOV를 해결 할 수 있다. 예들 들면, ‘왼손’, ‘왼편’은 ‘왼’과, 손’, ‘편’의 합성이므로 ‘왼’,’-손’,’-편’ 세 단어가 단어집(Vocab)에 있으면 '왼손’, ‘왼편’을 단어집(Vocab)에 넣지 않아도 토크나이징이 가능하다.
2) Domain Adaptation 방법

- DAPT가 제안된 이후로 관련된 연구들은 너무나도 많다. 다양한 방법이 있지만, 크게 3개로 제안되는 편이다. 필자는 "나의 노동 = 비용"이라 생각한다. 그래서 금융업에서 저비용 순으로 DAPT 했던 경험을 공유해보겠다!
- 먼저, 사용했던 방법론들을 설명하기 전에 상황을 가정해보자 (<- 이 상황은 과제로 수행된 내용이 절대 아니다.)
- 나에게 주어진 task는 sentence에서 신한은행에서 판매하는 "상품명" 을 tagging 하는 것이다. 즉, 상품명에 대한 NER을 수행하는걸 가정으로 하자.
- 학습 셋은 약 5천 문장이며, KoBERT로 NER을 학습해보니 f1-score가 90%가 나왔다.
- 라벨은 변경하지 않고, 성능을 더 올리고싶다.
- 상품과 관련된 코퍼스는 상품약관설명서 3만여건이 있다.1) only MLM
- 코퍼스 상품약관설명서를 특수문제 제거/sentence 단위의 split 등과 같은 일부 전처리를 거쳐 문장 단위로 만든다.
- 그 후, baseline 모델을 MLM 1~3 epoch 정도 학습시킨다.
- 성능이 오른다.
잘 만들어진 baseline에 기존 데이터 없이 학습하는 것은 위험한 짓이다. 하지만, MLM의 경우는 다르다. 모델링이 수행되며, 처음보는 단어들, UNK 토큰, positional embedding 등은 "아 이런 토큰 옆에 이런게 올 수도 있는거구나"가 학습되게 된다. 하지만, 경험상 성능이 오르긴 오르지만 약간은 미미한 수준 같다고 판단한다.
2) Extended vocab
- 코퍼스에서 자주 등장한 단어 top-K를 선정하여 기존 vocab에 추가하고, 해당 단어를 토크나이징의 우선순위로 둔다.
- 그 후, baseline 모델을 MLM 1~3 epoch 정도 학습시킨다.
- 토크나이저가 학습하지 않았는데, 잘 될까?
실제로 효과가 충분히 발생한다. 1) only MLM에서는 '이런 토큰 옆에 이런 토큰도 올 수 있음!'을 보여주는거라면, 2)에서는 '너 이 토큰 모르지? 근데 이 친구들 옆에는 이런 것들이 오니까 기억해놔' 를 알려준다. 이 방법은 1)보다 더 높은 성능 향상을 보여준다.
하지만, 코퍼스가 너무 관련성이 없으면 오히려 성능이 떨어지는 모습도 보여줬다. 예를 들어, downstream task는 상품명을 테깅하는 것인데 MLM 및 vocab을 구성한 코퍼스는 코스피 관련 투자 기사라면 성능이 더 떨어질 것이다. 이런 부분에선 전략이 필요하다.
그래서 정리해보면 "일단 task를 명확히 하고, 그 task 범위에 맞는 코퍼스를 수집해야 한다."
1) 먼저, 과제를 해결하기 위해 downstream task를 정의하고 baseline을 학습해본다.
2) 그 후, 테스트 셋의 결과들을 자세하게 뜯어보며 DAPT의 필요성을 파악해본다.
3) 관련된 코퍼스를 모아서 방법1을 시도해본다. 이 때, 만약 독자가 다루는 데이터가 금융 관련이라고 금융 데이터를 다 모으는건 낭비일 것이다. 해당 task와 관련된 코퍼스만 여럿 모아도 DAPT는 성공적이다. 그러니 downstream task를 명확히 할 필요가 있다.
4) 성능을 확인하고, 방법 2에 대한 실험을 진행해볼지 생각해본다.
5) 만약 내가 ShinhanBERT 같은걸 만들었더라면 "데이터는 다다익선!!" 이라고 하겠으나, 과제를 수행하기 위한 모델 성능 향상이 목적이라면 반대이다! (Document AI에선 방법2와 유사한 방식으로 큰 규모의 코퍼스로 RoBERTa를 DAPT하였고, 결과는 성공적이었다. 물론 PLM 대비 터무니 없이 부족한 데이터 양이었지만 전략을 잘 짰었다고 생각한다.)
4. Re-ranking에 필요한 이론 (SentenceBERT와 In-batch Random Negative Sampling)
- Re-ranking은 알아두면 정말 좋다. 금융은 on-premise 를 깔고가기 때문에 신규 프로젝트가 만들어졌을 때 검색엔진의 선택권이 거의 없다고 보면 된다. 즉, 있는걸 잘 써야한다. 그렇다는 것은 해당 프로젝트에 있어 "검색엔진 = 상수"이다. (<- 이건 순수한 나만의 의견이고, 다른 팀원 의견은 조금 달랐다. 만약, 독자가 이걸 보고 "앵? 개소리..." 라는 생각이 든다면 댓글로 반박을 부탁한다.. 나만의 생각에 갇힌 느낌ㅠㅠ 암튼 내가 검색을 잘 몰라서 그런걸 수도 있지만, 검색엔진은 상수가 분명하다. BM25 기반이라면 한계가 있는 것은 FACT!!! ES내에서 검색 인덱스를 좁힌다거나 필드를 변경한다거나 등등 이런거밖에 할 수 있는게 없지 않나......?) 또한, 네이버의 검색엔진처럼 로그 기반으로 운영된다면 최신성/관련성이 반영될테지만 우린 텍스트(즉, BM25)에만 의존할 수 밖에 없었다. 그렇기에 특정한 task가 있다면 그 task를 수행하기 위해 입맛에 맞는 ranking은 필연적이다. 나는 RAG를 하며 Re-ranking 전략을 짜본 적이 있다. 그때 수행한 실험이 SimCSE와 DPR 이었기에 두 개의 모델을 중심으로 설명해본다.
- 서론이 길었지만, 결론적으로 Re-ranking의 핵심 요소는 "비슷한 것들 사이에서 내가 원하는 정보를 찾자" 이다. 사용하는 검색엔진이 BM25라면 키워드 검색으로 나온 결과이기 때문에 쿼리의 검색 결과(top-10이라 가정)는 다 비슷할 것이다. 거기서 텍스트에만 의존하여 정답을 찾는건 쉽지 않은 일... 이 때, contrastive learning을 사용한다면 의미론적으로 비슷한 내용을 찾아낼 수 있지 않을까? 라는게 나의 가정이다. (<- 결론은 실험 결과가 좋았다.)
1) SimCSE와 DPR (Dense Passage Retrieval) 의 공통점
- 목적: 두 방법 모두 텍스트 데이터에서 의미론적으로 유사한 정보를 검출하고 이해하는 것을 목표로 한다.
- Feature training: 두 방법 모두 문장이나 단락의 의미를 효과적으로 포착할 수 있는 vector representation을 학습한다.
2) 차이점
- 목적과 응용 분야: SimCSE는 일반적인 문장 임베딩을 생성하는 데 초점을 맞추었고, 다양한 NLP 테스크에 적용할 수 있다. 하지만, DPR은 쿼리에 대한 가장 관련성 높은 문서를 검색하는데 초점을 맞추고 있다.
- 학습 방식: SimCSE는 SSL과 Contrastive learning을 사용하는 반면, DPR은 쿼리와 문서 간의 관계성을 학습한다.
- 모델 구조: SimCSE는 단일 인코더지만, DPR은 쿼리와 문서 각각의 인코더를 사용한다.
3) SimCSE의 핵심 요소
- Contrastive learning의 기본 개념: Contrastive learning에서는 유사한 샘플 (positive pairs) 사이의 거리를 줄이고, 다른 샘플 (negative pairs) 사이의 거리를 늘리는 것을 목표로 한다.
- SimCSE의 접근법: SimCSE는 이러한 양성 쌍과 함께 데이터 셋 내의 다른 문들들을 음성 샘플로 사용하여 contrastive loss를 계산한다.
- contrastive loss의 계산: 양성과의 유사성을 최대화, 음성과의 유사성은 최소화하도록 설계하며, 이 과정은 문장의 의미론적 유사성을 포착하는 벡터 임베딩을 생성하는 데 도움을 준다.
- Contrastive loss vs. Triplet loss
* 무뇌했던 나는 두 loss가 동일한줄 알았다ㅋㅋㅋ 근데 논문을 보아하니 아니었다ㅠㅠ 리마인드겸 그냥 적어보았다..
(1) Contrastive loss는 주로 하나의 양성 쌍과 여러 음성 쌍을 비교한다.

(2) Triplet loss는 한 개의 Anchor에 대해 하나의 Positive와 하나의 Negative 샘플을 비교한다.

4) Dense Passage Retrieval (DPR)의 핵심 요소
- 질의와 문서의 분리된 인코딩: DPR은 질의와 문서를 별도의 읜코더를 사용하여 인코딩한다. 이는 더 효율적인 검색을 가능하게 한다.
- 질의-문서 간의 연관성 학습: DPR은 주어진 질의에 가장 관련이 높은 문서를 식별하기 위해 질의와 문서 간의 연관성을 학습한다.
- In-batch Negative sampling
DPR은 사전에 데이터셋을 로드하는 SimCSE와는 달리, 학습 데이터의 현재 배치 내에서 음성 샘플링을 수행한다. 즉, 각 질의에 대해 동일한 배치 내의 다른 질의와 관련된 문서들을 음성 샘플로 활용한다.
각 훈련 스텝마다 배치가 변경되므로, 모델은 계속해서 다른 조합의 음성 샘플을 경험하게 되고, 이는 모델이 보다 다양한 시나리오에 적응하도록 돕는다.
DPR에서 In-batch Negative sampling은 다음과 같이 이루어지고, 그림을 참고하면 좋을거같다. (그림을 보면 알겠지만, batch가 클수록 샘플링이 많다. 즉, distibution을 높게 가져갈 수 있다는 의미이다. 이는 장비가 빵빵하면 좋은 성능을 보장한다는 뜻이다. 실제로 구글에서 어마어마한 batch size로 실험을 했다.)

(1) 질의와 문서 인코딩
(2) 음성 샘플 활용
(3) NLL loss 적용

'Deep-Learning > [NLP] 이론' 카테고리의 다른 글
[LLM 기초 다지기] LoRA for LLM Fine-tuning (0) 2023.11.09 [LLM 기초 다지기 ] Self Attention and Transformer (0) 2023.11.05 [LLM 기초 다지기] Attention Mechanism (0) 2023.11.03 [LLM 기초 다지기] Word Embeddings (0) 2023.10.30